Metodologie kalkulačky
Jak mzdová a platová kalkulačka vznikla?
Mzdová a platová kalkulačka vznikla v rámci projektu 22 % K ROVNOSTI Ministerstva práce a sociálních věcí (MPSV). Byla inspirována rakouskou verzí kalkulačky, která je v provozu od roku 2011 (https://www.gehaltsrechner.gv.at/). Jejím cílem je výpočet průměrného výdělku pro jedince se zadanými konkrétními parametry a také výpočet procentuálního rozdílu ve výdělcích žen a mužů na základě těchto parametrů.
Výpočty jsou stanoveny pouze pro zaměstnance a zaměstnankyně v pracovním poměru. Vzhledem ke kvalitní a velmi podrobné datové základně, kterou česká verze kalkulačky využívá, je možné výpočty stanovit odděleně pro mzdovou a platovou sféru (soukromý a veřejný sektor). Ve mzdové sféře se výpočty stanovují samostatně pro všechny hlavní třídy klasifikace zaměstnání CZ-ISCO s výjimkou hlavních tříd 6 a 9, které jsou pro tyto účely sloučeny. V platové sféře se výpočty samostatně stanovují pro hlavní třídy klasifikace CZ-ISCO 0,1,2 a 3, hlavní třídy 4-9 jsou pro tyto účely sloučeny.
Pro mzdovou sféru se vytváří 8 teoretických modelů pro pětimístné CZ-ISCO a stejné množství pro čtyřmístné CZ-ISCO. Obdobně se v platové sféře vytváří 5 teoretických modelů pro pětimístné a shodné množství pro čtyřmístné CZ-ISCO. Tím je vytvořeno 26 základních teoretických regresních modelů. Tyto modely dále existují v totožné podobě odděleně pro ženy, muže a celkem, kalkulačka tedy pracuje celkem se 78 teoretickými regresními modely.
Tento postup umožňuje stanovit přesnější výpočty pro odlišné skupiny profesí, které se výrazně liší výší a variabilitou výdělků, ale zejména charakteristikami zaměstnanců (vzdělání, věk apod.).
Metodika kalkulačky vznikla a byla ověřena na datech z roku 2016. Data jsou každoročně aktualizována, kalkulačka pracuje s daty z předchozího uzavřeného roku. Výstupy z kalkulačky jsou zveřejněny na webových stránkách https://rovnaodmena.cz/rovne-odmenovani/kalkulacka/.
S jakými daty kalkulačka pracuje?
Kalkulačka využívá harmonizovaná celoroční data z Informačního systému o průměrném výdělku (ISPV). ISPV je systém pravidelného monitorování výdělkové úrovně a pracovní doby zaměstnanců a zaměstnankyň v České republice. ISPV obsahuje údaje z pravidelného statistického šetření, které je pod názvem Čtvrtletní šetření o průměrném výdělku zařazeno do programu statistických zjišťování vyhlášených Českým statistickým úřadem (ČSÚ) ve sbírce zákonů pro příslušný kalendářní rok. Poskytnutí dat je tedy pro vybrané firmy a organizace povinné, čímž je dosažena vysoká kvalita dat. ISPV v současnosti zahrnuje data o cca 70 % všech zaměstnaných, teoretické modely kalkulačky však pokrývají více než 80 % zaměstnanecké populace. Hlavními sledovanými ukazateli jsou z hlediska výdělkové úrovně hrubá měsíční mzda/plat a hodinový výdělek. Dále jsou sledovány složky mzdy/platu (tj. odměny, příplatky a náhrady) a úroveň a struktura odpracované (např. přesčas) a neodpracované doby (např. nemoc a dovolená). Nezbytnou součástí ISPV je Regionální statistika ceny práce (RSCP), která poskytuje detailní přehled o odlišnostech mzdové úrovně v jednotlivých krajích ČR. Gestorem Čtvrtletního šetření o průměrném výdělku je Ministerstvo práce a sociálních věcí (MPSV). Zpracovatelem ISPV je TREXIMA, spol. s. r. o.
Jaké údaje kalkulačka zohledňuje?
Jak již bylo řečeno, kalkulačka odlišuje sféry ekonomických činností, mzdovou a platovou (soukromý a veřejný sektor). V každé sféře dále odlišuje sektory (skupiny) ekonomických činností a následně samotné profese.
Trh práce byl rozdělen do 23 sektorů (skupin) podle podobnosti vykonávané činnosti ve vazbě na klasifikaci zaměstnání CZ-ISCO. Pro každý sektor byly vybrány typické kódy zaměstnání CZ-ISCO zvlášť pro mzdovou a zvlášť pro platovou sféru. Z těchto typických kódů byly následně do kalkulačky vybrány podskupiny a kategorie zaměstnání (4 a 5místné kódy CZ-ISCO) dle publikačních kritérií ISPV a RSCP a dle předpokládané srozumitelnosti pro uživatele. Celkový počet vstupních kódů pro mzdovou i platovou sféru je cca 580. Pro každý kód zaměstnání CZ-ISCO byl stanoven srozumitelný název profese, který si mohou uživatelé a uživatelky v kalkulačce vybrat. Názvy jsou stanoveny zvlášť pro mzdovou a zvlášť pro platovou sféru.
Další sledované parametry pak jsou základní sociodemografické údaje, nejvyšší dosažené vzdělání, věk a kraj. Ve mzdové sféře je navíc sledována ještě velikost ekonomického subjektu dle počtu zaměstnanců a zaměstnankyň (v platové sféře tato proměnná není pro stanovení výše platu významná a není proto do výpočtů zahrnuta).
Nejvyšší dosažené vzdělání je rozděleno do pěti skupin (shodně s publikacemi ISPV, pouze bez kategorie „Neuvedeno“). Jedná se o vzdělání: základní a nedokončené, střední bez maturity, střední s maturitou, vyšší odborné a bakalářské, vysokoškolské.
Jelikož se s věkem nemění výše průměrného výdělku lineárně, ale jejich vztah představuje spíše obrácené písmeno “U“, tedy nejprve s věkem průměrný výdělek roste a od určitého věku opět klesá, je věk v modelu popsán také formou paraboly (věk a druhá mocnina věku).
Proměnná kraj obsahuje standardních 14 krajů dle číselníku NUTS 3, tj. Hlavní město Praha, kraje Středočeský, Jihočeský, Plzeňský, Karlovarský, Ústecký, Liberecký, Královéhradecký, Pardubický, Olomoucký, Moravskoslezský, Jihomoravský, Zlínský a Vysočina.
Dělení dle velikosti ekonomického subjektu má pět skupin: 1-9 zaměstnanců, 10-49 zaměstnanců, 50-249 zaměstnanců, 250-999 zaměstnanců a 1000 a více zaměstnanců.
Co kalkulačka dělá?
Kalkulačka pracuje na bázi lineárního regresního modelu. Závisle proměnná, tedy vysvětlovaná proměnná je výše mzdy/platu, přesněji přirozený logaritmus hrubé měsíční mzdy/platu (značíme lnMzda). Nezávisle proměnné, tedy vysvětlující proměnné jsou sledované parametry jako je sféra, sektor, profese, nejvyšší dokončené vzdělání, věk, region a velikost ekonomického subjektu).
Základním předpokladem modelu je, že závisle proměnná má normální rozdělení a nezávisle proměnné mají multiplikativní efekt, tedy se nepředpokládají žádné interakce mezi proměnnými, efekty jednotlivých vysvětlujících proměnných se sečtou, a tím získáme jejich celkový efekt na závisle proměnnou.
Počet pozorování (počet vybraných zaměstnanců) značíme písmenem η, pro i-tého zaměstnance či zaměstnankyni má model tvar
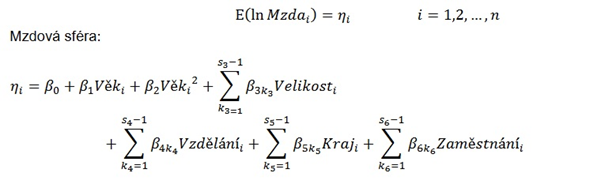
kde ηi je regresní funkce (podmíněná střední hodnota přirozeného logaritmu hrubé měsíční mzdy nebo platu vzhledem k různým kombinacím hodnot vysvětlujících proměnných jako je Věk, Velikost, Vzdělání, Kraj, Zaměstnání), β0 je konstanta , βj je parametr pro j-tou vysvětlující spojitou proměnnou, proměnou (Věk), βjk je parametr, který přísluší k-té kategorii j-té vysvětlující proměnné (j=1,2,…,m,kj=0,1,…,sj−1). U kategoriálních proměnných (Velikost, Vzdělání, Kraj, Zaměstnání) označujeme indexem kj= 0 referenční kategorii. Vysvětlující kategoriální proměnné jsou umělé proměnné, které nabývají pouze hodnot 1 v případě, že i-tý zaměstnanec je zařazen v k-té kategorii j-té vysvětlované proměnné, jinak nabývá hodnoty 0.
Velmi zjednodušeně lze odhad podmíněné střední hodnoty přirozeného logaritmu hrubé měsíční mzdy považovat za odhad průměrné hodnoty logaritmu hrubé měsíční mzdy/platu. Zpětnou transformací logaritmu (exponováním) získáme odhad průměrné hodnoty hrubé měsíční mzdy/platu, stručněji odhad průměrné mzdy.
Jelikož se zaměstnanecká populace ve veřejném a soukromém sektoru (platové a mzdové sféře) významně liší, a to především vzdělanostní a profesní strukturou (vyšší podíl vysokoškolsky vzdělaných a nižší podíl dělnických profesí v platové sféře oproti mzdové sféře), bylo nutné stanovit pro obě sféry regresní rovnice odděleně. Rovnice pro mzdovou sféru obsahuje navíc ještě jeden člen, a to velikost ekonomického subjektu, který v platové sféře nehraje roli.
Odhadují se hodnoty průměrných mezd bez předpokládaného vlivu pohlaví, a poté velikosti průměrných mezd s předpokládaným vlivem pohlaví. Muži a ženy se na trhu práce liší především vzdělanostní a profesní strukturou. I zde je vhodné respektovat odlišnou strukturu ve mzdách a spočítat regresní rovnice pro muže a ženy zvlášť. Tento postup zohledňuje i výpočet mzdového rozdílu, který bude více odpovídat zadaným kombinacím hodnot vysvětlujících proměnných.